AI Blog Writing Agent
Autonomous multi-agent system that researches the web and writes comprehensive, structured blog posts — powered by LangGraph, Groq (LLaMA 3), and Tavily Search
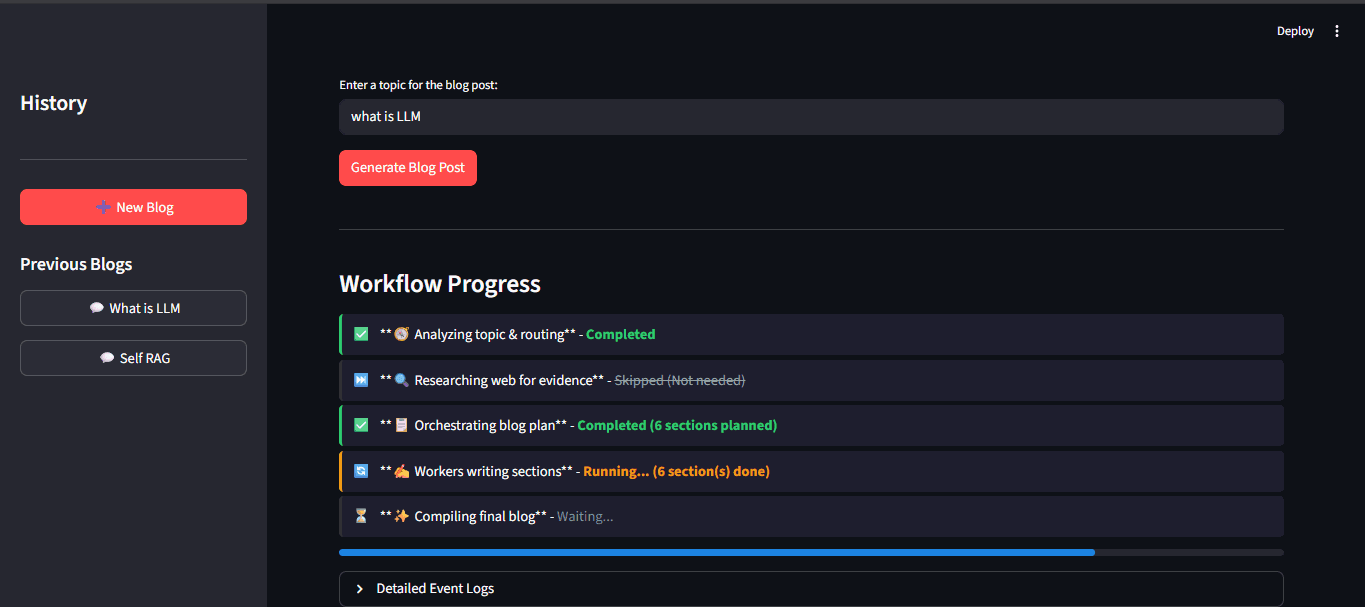
An autonomous, multi-agent blog writing pipeline that takes a single topic as input and produces a fully-written, research-backed blog post — automatically. Unlike a simple prompt-to-text setup, this system uses a graph-based multi-agent workflow powered by LangGraph where specialized agents collaborate.
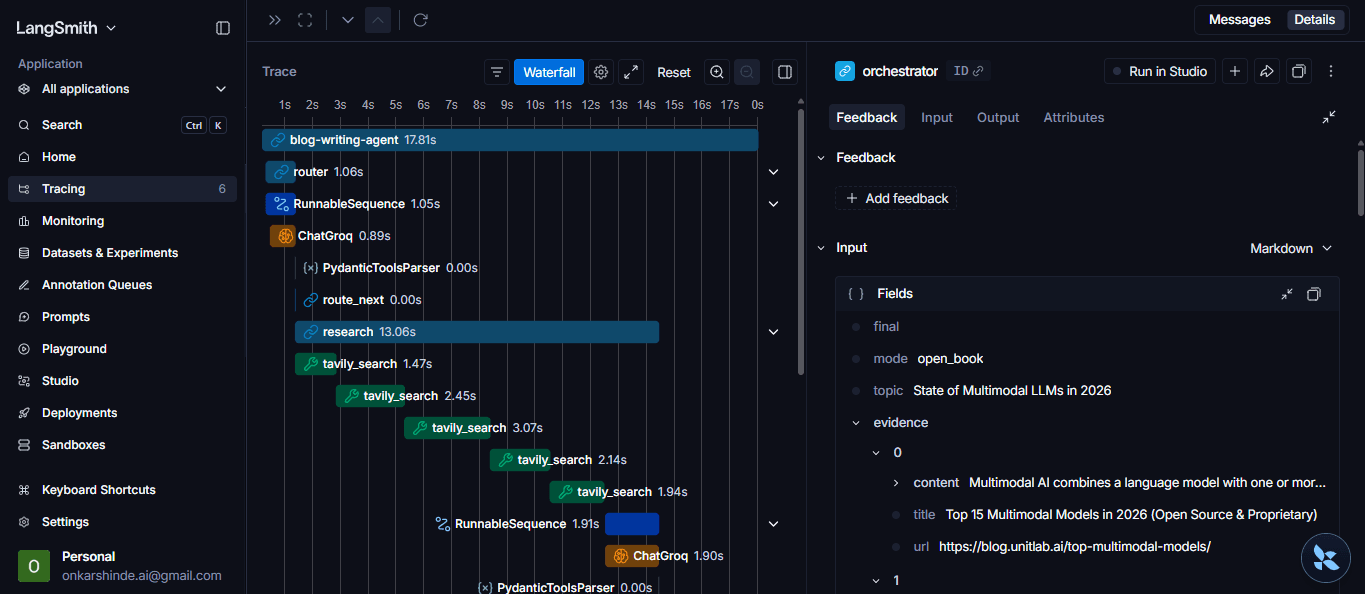
The Router agent decides whether the topic needs live web research via Tavily Search API or can be answered from LLM knowledge. The Orchestrator plans the complete blog structure — title, sections, tone, target audience, and word-count targets. Multiple Worker agents then write each section simultaneously using LangGraph's fan-out pattern, and a Reducer stitches them into a final polished post.
The result is a production-quality blog post with a one-click Markdown download option. All past blogs are instantly accessible in a ChatGPT-style sidebar history — every generation is stored independently via SQLite-backed LangGraph checkpointing so there's no context bleed between posts. The entire pipeline is fully observable with LangSmith tracing.
START
│
▼
┌─────────┐
│ Router │ ← Decides: research needed? (yes/no)
└─────────┘
│ \
▼ ▼ (if no research needed)
┌──────────┐ │
│ Research │ │ ← Tavily real-time web search
└──────────┘ │
│ │
└──────┬──────┘
▼
┌─────────────┐
│ Orchestrator│ ← Plans blog sections
└─────────────┘
│
(fan-out to N parallel workers)
│
┌──────┴──────┐
▼ ▼ ▼ ▼
[W1][W2][W3][W4] ← Workers (each writes one section)
└──────┬──────┘
▼
┌─────────┐
│ Reducer │ ← Merges all sections into final blog
└─────────┘
│
END 1 / 4
1 / 4